Les processeurs ne sont rien d’autres que des machines à calculer (un peu évoluées) programmables. Imaginez que vous êtes comptable, et que vous ayez à effectuer une série d’opérations qu’on vous a gentiment inscrites sur une feuille de papier. Voici un exemple d’instructions qu’on peut vous avoir donné :
faire 112 + 3
faire 4 + 5
faire 2 + 16
…
Un exemple un peu plus compliqué serait :
faire 112 + 2
faire “résultat précédent” * 5
…
ou bien
112 + 3
résultat précédent - 4
si le résultat est nul, passer à l’étape 6, sinon continuer
3 * 4
résultat précédent + 9
ouvrir la fenêtre
résultat de l’étape 2 - 15
passer à l’étape 12
…
Un microprocesseur est un dispositif électronique qui pourrait faire ce travail à votre place, pourvu qu’on lui donne la feuille de papier (et de l’énergie).
Les séries d’opérations ci-dessus sont appelées programmes. En d’autres termes, un programme de microprocesseur est juste une liste d’opérations à effectuer. Dans notre cas, où le microprocesseur est simple, les instructions resteront simples et en petit nombre.
Dans la littérature, on nomme ce genre de processeur "processeur RISC" (pour Reduced Instruction Set Computer).
Si le processeur est plus complexe, incluant des périphériques multiples (gestionnaire de mémoire, entrées-sorties, …), les instructions peuvent devenir très complexes et très nombreuses. La dénomination consacrée à ce genre de processeur est CISC (pour Complex Instruction Set Processor).
Dans les suites d’opérations ci-dessus, on distingue deux types d’objets :
les données :
d’abord les opérandes proprement dits (“3”, “4”, “112”, …),
et les opérandes implicites (“résultat précédent”, “résultat de l’étape 2”, …);
les instructions :
pour nous ce sont principalement les opérations (au sens arithmétique du terme) à effectuer (“+”, “−”, “*”, “/”...),
il y a aussi des tests (“si le résultat précédent est nul...”),
et des sauts, conditionnés par un test (“alors passer à l’étape 6”) ou non (“passer à l’étape 12”)
ainsi que des instructions spéciales (“ouvrir la fenêtre”). Dans notre cas, une instruction de ce genre pourrait être “mettre en marche le buzzer”, ou “allumer la LED numéro 10”...
Notez que ces suites d’opérations sont numérotées : elles ont un ordre. Dans le premier exemple, l’ordre n’a pas tellement d’importance, mais il en a une dans le deuxième et le troisième quand on parle de “résultat précédent”, d’“étape 6”, …
Passons du comptable et de la feuille de papier aux composants électronique.
La feuille de papier a un rôle de mémorisation :
c’est sur elle qu’est écrite la suite d’opérations à effectuer,
c’est probablement aussi sur elle que seront écrit les résultats.
Nous la modéliserons par une mémoire vive, une RAM (pour Random Access Memory). C’est cette RAM qui stockera les instructions à effectuer, les données, ainsi que les résultats que le microprocesseur va calculer. Le microprocesseur sera donc relié à cette RAM, et ira lire les instructions à effectuer, selon le principe suivant :
aller lire la première ligne (instructions et données associées)
faire ce qui est indiqué
aller lire la ligne suivante (instructions et données associées)
faire ce qui est indiqué
revenir à l’étape 3 (etc. jusqu’à ce que mort s’ensuive...)
Première remarque
: le microprocesseur doit lire les lignes une par une. Il doit donc maintenir un compteur de ligne interne qui indique la ligne courante (ou la prochaine ligne à lire, comme cela nous arrangera).
Deuxième remarque
: le processeur est un dispositif électronique qui ne comprend que des suites de bits. Il faudra donc coder les instructions sur un nombre de bit suffisant pour coder toutes les instructions dont nous aurons besoin. Les données seront limitées à des entiers naturels (positifs) et il faudra trouver un moyen de coder les données implicites.
Troisième remarque
: dans notre architecture, la RAM stockera les données et les instructions de façon imbriquée. Il est possible d’utiliser deux RAM différentes, ou des zones distinctes, mais ce n’est pas l’objet de ce cours.
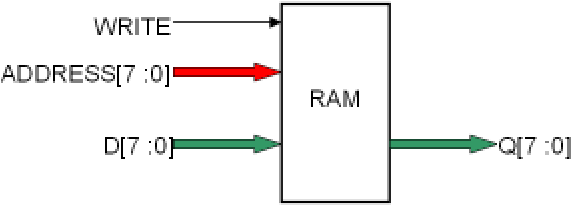
un bus d’adresses, ADDRESS[7:0] indiquant l’emplacement en mémoire de la donnée à laquelle on accède,
un bus de donnée, D[7:0], pour les données qu’on écrit en RAM,
un bus de donnée, Q[7:0], pour les données qu’on va lire en RAM,
ainsi que
un signal de contrôle sur 1 bit, WRITE, indiquant si on est entrain de faire une lecturedans la RAM (WRITE=0), ou une écriture (WRITE=1).
Le fonctionnement de la RAM est le suivant :
la RAM sort en permanence sur Q[ ] la donnée stockée à l’adresse présente sur ADRESSE[ ]
(après, Q[ ], on en fait ce qu’on veut... Si on n’a pas envie de l’utiliser, on l’ignore),
si WRITE est actif (1), la valeur présente sur D[ ] est stockée à l’adresse présente sur ADRESSE[ ],
si WRITE est inactif (0), D[ ] est ignoré.
De plus, pendant que WRITE est actif, le bus Q[ ] prend la même valeur de D[ ].
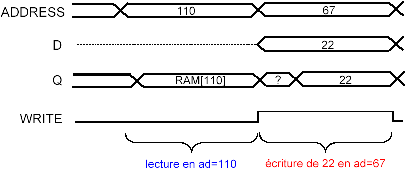
Pour les chronogrammes, on se reportera à la figure 1.2
Figure 1.2: Exemple d'accès à la RAM
Nous relierons notre microprocesseur (automate) à une RAM pouvant stocker 256 mots de 8 bits chacun :
8 bits : les lignes de données D[ ] seront un bus 8 bits
256 mots : il nous faudra donc 8 bits d’adresse (pour coder une adresse allant de 0 à 255)
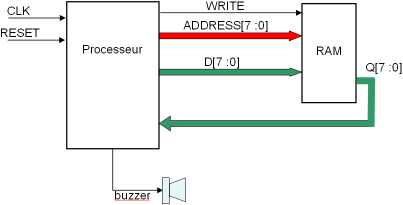
L’architecture globale, qui nous re-servira en TP est donc la suivante (voir figure 1.3)
notre microprocesseur
la RAM, reliée au processeur par ses bus de données, adresses et la ligne de WRITE
un buzzer qui servira à jouer de la musique
Figure 1.3: schéma global
1. Étape 1 : Un automate linéaire basique
Dans cette première étape, nous n’implémenterons que les instructions et données du premier exemple. Le processeur est donc relié à une mémoire vive (RAM) stockant 256 mots de 8 bits.
On suppose que le programme (opérations à effectuer) ainsi que les données sont déjà chargées dans la mémoire, et qu’ils respectent le format suivant :
adresse
type du mot stocké
exemple
0
instruction
+
1
donnée (premier opérande)
3
2
donnée (deuxième opérande)
4
3
donnée (résultat)
X
4
instruction
-
5
donnée (premier opérande)
12
6
donnée (deuxième opérande)
8
7
donnée (résultat)
X
Le “X” indique que la RAM ne contient rien de valide à cet endroit là. C’est au microprocesseur d’aller y écrire le résultat correct. Après avoir lancé le microprocesseur, le contenu de la RAM sera donc le suivant (on indique en gras les endroits de la RAM qui ont changé) :
adresse
type du mot stocké
exemple
0
instruction
+
1
donnée (premier opérande)
3
2
donnée (deuxième opérande)
4
3
donnée (résultat)
7
4
instruction
-
5
donnée (premier opérande)
12
6
donnée (deuxième opérande)
8
7
donnée (résultat)
4
Remarques :
le microprocesseur doit commencer son exécution à l’adresse 0 de la mémoire,
on part donc du principe qu’on aura donc toujours une instruction à l’adresse 0 de la mémoire,
et qu’on aura toujours en mémoire une instruction, puis l’opérande 1, puis l’opérande 2, puis un octet pour stocker le résultat
Ces opérations arithmétiques opèrent sur des nombres de 8 bits, représentant des entiers non signés. Les instructions étant stockées en RAM, il est nécessaire de les coder. Comme la RAM stocke des mots de 8 bits, ça nous donne 256 instructions possibles, ce qui est largement suffisant pour un processeur basique... Le code choisi ci-dessus pour l’addition et la soustraction est parfaitement arbitraire : il correspond à celui qui sera implémenté en TP.
Vue l’organisation de la RAM qui a été choisie, le fonctionnement de l’automate est simple : à chaque coup d’horloge, il va chercher successivement une instruction, puis le premier opérande, puis le deuxième opérande, calcule le résultat et le stocke. Puis il recommence à l’adresse suivante.
En détail :
Premier coup d’horloge : le microprocesseur présente l’adresse “0” à la RAM.
La RAM lui présente donc sur son bus de sortie le contenu de l’adresse 0, qui est la première instruction.
Deuxième coup d’horloge : le microprocesseur incrémente l’adresse qu’il présente à la RAM (“1”).
La RAM lui présente donc sur son bus de sortie le contenu de l’adresse 1, qui est le premier opérande.
Troisième coup d’horloge : le microprocesseur incrémente l’adresse qu’il présente à la RAM (“2”).
La RAM lui présente donc sur son bus de sortie le contenu de l’adresse 2, qui est la deuxième opérande.
A ce moment là, le microprocesseur dispose de toutes données nécessaire au calcul : l’instruction, et les deux opérandes. Il peut donc calculer le résultat.
Quatrième coup d’horloge : le microprocesseur incrémente l’adresse qu’il présente à la RAM (“3”).
Parallèlement, il présente sur le bus de donnée en entrée de la RAM le résultat qu’il vient de calculer.
Parallèlement, il passe la ligne WRITE de la RAM à l’état haut, pour dire à la mémoire qu’il désire effectuer une écriture.
Le résultat du calcul est donc à ce moment là écrit à l’adresse “3” de la mémoire.
Cinquième coup d’horloge : le microprocesseur incrémente l’adresse qu’il présente à la RAM (“4”).
La RAM lui présente donc sur son bus de sortie le contenu de l’adresse 4, qui est la deuxième instruction.
etc...
Question 1:
Concevoir l’architecture de cet automate.
On ne demande pas une représentation de toutes les portes logique de l’automate, mais juste une représentation de haut niveau : vous disposez de registres, de boites combinatoires dont vous ne donnerez que les équations, de multiplexeurs, de compteurs, etc.
Nous allons doter notre processeur d’un registre interne sur 8 bits, que nous appellerons accumulateur. Toutes les opérations arithmétiques à deux opérandes s’effectueront entre l’accumulateur et une donnée en RAM. Plus précisément : pour effectuer “3 + 4” et stocker le résultat en RAM, le processeur effectuera les instructions suivantes :
chargement de 3 dans l’accumulateur
addition de l’accumulateur avec un opérande en RAM (“4”)
stockage du contenu de l’accumulateur en RAM
Pour effectuer “3 + 4 + 5” :
chargement de 3 dans l’accumulateur
addition de l’accumulateur avec un opérande en RAM (“4”)
addition de l’accumulateur avec un opérande en RAM (“5”)
stockage du contenu de l’accumulateur en RAM
On ajoute donc deux instructions à notre processeur :
load : chargement de l’accumulateur à partir de la RAM
store : stockage du contenu de l’accumulateur dans la RAM
Parallèlement, les instructions d’addition et de soustraction n’ont plus besoin que d’un seul opérande - le deuxième opérande est dans l’accumulateur.
De plus, tant qu’on y est, nous allons ajouter trois instructions de manipulation de bits : AND, OR et XOR (cf. le tableau 1.1), qui comme l’addition, opèrent sur le contenu de l’accumulateur et un opérande en RAM.
Le nouveau jeu d’instruction devient donc :
Tableau 1.1: Nouveau jeu d'instructions
code (binaire 8 bits)
instruction
effet
00000001
XOR
Effectue un XOR bit à bit entre le contenu de l’accumulateur et une donnée en RAM; le résultat est stocké dans l’accumulateur
00000010
AND
Effectue un ET bit à bit entre le contenu de l’accumulateur et une donnée en RAM; le résultat est stocké dans l’accumulateur
00000011
OR
Effectue un OU bit à bit entre le contenu de l’accumulateur et une donnée en RAM; le résultat est stocké dans l’accumulateur
00000100
addition
Additionne le contenu de l’accumulateur à une donnée en RAM; le résultat est stocké dans l’accumulateur
00000110
soustraction
Soustrait du contenu de l’accumulateur une donnée en RAM; le résultat est stocké dans l’accumulateur
00001010
load
Charge dans l’accumulateur une donnée en RAM
00001011
store
Stocke le contenu de l’accumulateur en RAM
Question 3: Quel est l’impact de ces spécifications sur la façon de stocker le programme en RAM ?
Question 4: Concevoir la nouvelle architecture du processeur. Quels sont les avantages en terme de vitesse par rapport à l’architecture précédente ?
3. Étape 3 : Un automate avec accumulateur et indirection
Imaginez qu’on souhaite séparer le code des données, pour :
faire tourner un même code sur des données différentes (sans le dupliquer pour chaque set de donnée...)
faire tourner différents codes sur des mêmes données (sans dupliquer les sets de données...)
faire tourner un code sur des données qui ne sont pas connues avant l’exécution du programme (du genre, le début du programme demande à l’utilisateur d’entrer des valeurs...)
Pour le moment, notre processeur ne sait pas faire : on doit connaître les données au moment du pré-chargement de la RAM avec le code...
Il faudrait disposer d’instructions de manipulation du contenu de la RAM à des endroits arbitraires (on ne modifierait que des données, hein, pas le code...) Cela permettrait d’aller modifier les zones où se trouvent les opérandes. Mais c’est peut-être un peu compliqué d’avoir à modifier plein de zones éparses.
Pour être plus propre, on pourrait séparer le code des données. On aurait, en RAM, une zone avec les instructions et une zone avec les données. Il suffirait juste d’aller modifier la zone des données, et d’exécuter le code générique qui saurait, pour chaque instruction, où trouver les bons opérandes.
Pour cela, on modifie (toutes) les instructions de la façon suivante : au lieu d’avoir en RAM deux octets instruction - opérande, on aura plutôt instruction - adresse de l’opérande.
Par exemple, pour effectuer “3 + 4, 3 − 1” on pourra voir une organisation du genre (voir tableau 1.2):
Tableau 1.2: Organisation de la mémoire, avant éxécution du programme
adresse
type du mot stocké
exemple
zone
0
instruction
load
1
adresse de l’opérande
100
2
instruction
+
3
adresse de l’opérande
101
4
instruction
store
5
adresse de l’opérande
103
6
instruction
load
zone de code
7
adresse de l’opérande
100
8
instruction
-
9
adresse de l’opérande
102
10
instruction
store
11
adresse de l’opérande
104
…
…
…
100
donnée
3
101
donnée
4
102
donnée
1
zone de données
103
donnée
X
104
donnée
X
…
…
…
Après l’exécution du code, on aura ceci en RAM (voir tableau 1.3)
Tableau 1.3: Organisation de la mémoire, après exécution du programme
adresse
type du mot stocké
exemple
zone
0
instruction
load
1
adresse de l’opérande
100
2
instruction
+
3
adresse de l’opérande
101
4
instruction
store
5
adresse de l’opérande
103
6
instruction
load
zone de code
7
adresse de l’opérande
100
8
instruction
-
9
adresse de l’opérande
102
10
instruction
store
11
adresse de l’opérande
104
…
…
…
100
donnée
3
101
donnée
4
102
donnée
1
zone de données
103
donnée
7
104
donnée
2
…
…
…
Remarque : d’habitude on sépare même la zone de données en deux, celles qui sont connues à l’écriture du programme, et les autres (celles qui sont modifiées par le programme)...
Question 5: Proposer une modification de l’automate pour que les instructions travaillent avec des adresses d’opérandes...
4. Étape 4 : Un processeur RISC
L’architecture actuelle ne sait effectuer que des calculs linéaires (suite fixe d’instructions), sur des données potentiellement inconnues (mais dont les adresses en mémoire sont connues)
Nous allons maintenant lui ajouter des instructions de saut conditionnels (et, tant qu’on y est, inconditionnels)
Chaque opération (logique ou arithmétique) va positionner deux signaux appelés Flags (ou drapeaux) devant être mémorisés pour l’instruction suivante.
Ces drapeaux ne doivent être modifiés que si on modifie l’accumulateur. Ils sont nommés:
C (comme carry) :
mis à 1 si l’opération courante est une opération arithmétique et donne lieu à une retenue,
mis à 0 si l’opération courante est une opération arithmétique et ne donne pas lieu à une retenue,
mis à 0 si on fait un load
Z (comme zéro) :
mis à 1 si on charge 0 dans l’accumulateur
mis à 0 dans tous les autres cas.
Question 6: Implémenter la gestion des drapeaux, et rajouter deux opérations ADDC et SUBC, prenant en compte la retenue C de l’opération précédente (pour implémenter des additions / soustractions sur des grands nombres par exemple).
4.2 Sauts
Pour implémenter les sauts, on définit trois instructions supplémentaires :
JMP : saut inconditionnel.
L’exécution de cette instruction fait sauter l’exécution du programme directement à une adresse donnée (passée comme opérande).
JNC : saut si C est nul.
Idem à JMP, mais seulement si C est nul. Sinon, équivalent à NOP (on continue à l’adresse suivante)
JNZ : saut si Z est nul.
Idem à JMP, mais seulement si Z est nul. Sinon, équivalent à NOP (on continue à l’adresse suivante)
Question 7: Modifier l’architecture du processeur pour implémenter les sauts.
Tant qu’on y est, pour disposer de pauses, on définit l’instruction NOP, qui ne fait rien.
Question 8: Comment l’implémenter de façon simple ?
On ajoute aussi deux instructions, de rotation de bits (vers la droite ou vers la gauche en incluant le bit de retenue) :
ROL : ACC[7:0] devient ACC[6:0],C et C devient ACC[7]
ROR : ACC[7:0] devient C, ACC[7:1] et C devient ACC[0]
De plus, pour tester ce processeur lors du TP, on ajoute un port de sortie : c’est un ensemble de broches dont on veut pouvoir piloter l’état (passer certaines d’entre elles à l’état haut ou bas). Pour nous, il s’agit de piloter un buzzer, donc une seule sortie suffira.
Le jeu d’instruction devient donc (tableau 1.4) :
Tableau 1.4: Nouveau jeu d'instructions
code
(binaire 8 bits)
instruction
effet
explication
00000000
NOP
ne fait rien !
00000001
XOR
Acc = Acc XOR (AD)
effectue un XOR bit à bit entre le contenu de l’accumulateur et une donnée en RAM, le résultat est stocké dans l’accumulateur
00000010
AND
Acc = Acc AND (AD)
effectue un ET bit à bit entre le contenu de l’accumulateur et une donnée en RAM, le résultat est stocké dans l’accumulateur
00000011
OR
Acc = Acc OR (AD)
effectue un OU bit à bit entre le contenu de l’accumulateur et une donnée en RAM, le résultat est stocké dans l’accumulateur
00000100
ADD
Acc = Acc + (AD)
additionne le contenu de l’accumulateur à une donnée en RAM, le résultat est stocké dans l’accumulateur
00000101
ADC
Acc = Acc + (AD) + C
additionne le contenu de l’accumulateur à une donnée en RAM et à la carry C, le résultat est stocké dans l’accumulateur
00000110
SUB
Acc = Acc - (AD)
soustrait du contenu de l’accumulateur une donnée en RAM, le résultat est stocké dans l’accumulateur
00000111
SBC
Acc = Acc - (AD) - C
soustrait du contenu de l’accumulateur une donnée en RAM et la carry C, le résultat est stocké dans l’accumulateur
00001000
ROL
Acc = {Acc[6:0], C} et C = Acc[7]
effectue une rotation vers la gauche des bits de l’accumulateur
00001001
ROR
Acc = {C, Acc[7:1] } et C devient Acc[0]
effectue une rotation vers la droite des bits de l’accumulateur
00001010
LDA
Acc = (AD)
charge dans l’accumulateur une donnée en RAM
00001011
STA
(AD) = Acc
stocke le contenu de l’accumulateur en RAM
00001100
OUT
BZ = (AD)[0]
Sort sur la broche BZ le bit de poids faible de la donnée en RAM, stockée à l’adresse opérande
00001101
JMP
PC = AD
saute à l’adresse opérande
00001110
JNC
PC = AD si C=0
saute à l’adresse opérande si C est nul, ne fait rien sinon
00001111
JNZ
PC = AD si Z=0
saute à l’adresse opérande si Z est nul, ne fait rien sinon
Remarques :
AD est le deuxième octet (en RAM) de l’instruction
(AD) est la valeur en RAM stockée à l’adresse AD
Question 9: Finir le processeur…
5. Étape 5 : Optimisation de l'architecture
Question 10: Certaines opérations peuvent s’exécuter en moins de cycles. Lesquelles, en combien de cycles ? Modifier le processeur de façon à optimiser son temps de fonctionnement.
Question 11: Partant du principe que certaines opérations n’ont pas besoin d’opérande (NOP, ROT, ROR), pourquoi ne pas réduire la taille du code en RAM ?
Question 12 : On veut non seulement augmenter le nombre de sorties, disons à 16, mais aussi à pouvoir utiliser certaines d’entre elles non pas comme des sorties mais comme des entrées. Et ce, de façon dynamique : au cours du programme, une broche peut devenir un sortie, puis une entrée, puis une sortie etc. Comment l’implémenter?
Question 13: Comment modifier le processeur pour supporter une taille mémoire de 161024 mots (10 bits) ?
6. Étape 6: Récapitulons : le jeux d'instructions et le langage assembleur
Dans la prochaine séance, nous construirons d'une manière pratique le nanoprocesseur. Pour préparer cette séance, attardons nous sur son jeu d'instruction et la notion de langage assembleur.
Prenons la peine, d'examiner en détail ce jeu d'instruction, et l'usage qui peut être fait de chaque instruction.
Le langage assembleur
Dans les différentes étapes, nous avons eu l'occasion de décrire des programmes simples pouvant être exécutés par le nanoprocesseur. La version humainement lisible de tels programmes s'appelle le "langage assembleur". Ce type de langage est propre à chaque type de processeur puisque directement dépendant caractéristiques des processseurs. Néamoins tous les langages assembleurs ont un certain nombre de caractéristiques communes. Dans notre cas, les caractéristiques sont les suivantes
Chaque ligne correspond à une instruction
Chaque ligne comprend plusieurs champs:
Une étiquette éventuelle permettant d'associer un mnémonique à une adresse particulière dans un programme.
Le mnémonique de l'instruction
L'adresse de l'argument de l'instruction, qui peut être elle même représentée par un mnémonique, un nombre, ou éventuellement une expression arithmétique simple
Enfin, pour définir des zones de données, nous disposons d'une "directive" (.db pour define byte)
Ainsi, écrit, un tel langage peut être traité automatiquement pour générer le code binaire du programme devant être traité par le nanoprocesseur.
Prenons la peine d'examiner tout d'abord le programme de test du nanoprocesseur qui teste chacune des instructions, ainsi que le programme musical qui servira à la démonstration finale.
Réponses
Voici les réponses aux différentes questions
Réponse 1
La première réponse est très détaillée. Les autre réponses seront plus succinctes.
Pour effectuer un calcul, l’automate doit disposer de trois informations :
l’instruction (l’opération)
l’opérande 1
l’opérande 2
Plus que ça, il doit en disposer en même temps. Mais elles sont stockées en RAM, et ne peuvent être lues que l’une après l’autre. Il faudra donc prévoir un moyen de stockage de ces trois informations à l’intérieur du processeur pour pouvoir effectuer le calcul.
Vu l’organisation de la mémoire, il semble logique de lire ces trois informations de la façon la plus simple possible, c’est à dire :
tout d’abord l’instruction,
puis l’opérande 1,
puis l’opérande 2,
ce qui correspond à un parcours linéaire de la mémoire.
De plus, le stockage du résultat s’effectue dans la RAM à l’adresse suivant celle de l’opérande 2. On peut donc doter l’automate d’un compteur qu’on appellera compteur d’adresse ou PC (Program Counter), qui donnera l’adresse de la RAM à laquelle on est en train d’accéder (que ce soit en lecture ou en écriture). Ce compteur sera incrémenté à chaque coup d’horloge, et pilotera directement le bus d’adresse de la RAM.
Vu ce qui vient d’être dit, l’automate a un fonctionnement linéaire - l’ordre des actions effectuées est toujours le même :
chercher une instruction
chercher le premier opérande
chercher la deuxième opérande
stocker le résultat du calcul
On peut donc le concevoir comme un automate à quatre états, dont le fonctionnement est circulaire : état 1 → état 2 → état 3 → état 4 → état 1 → état 2 → …
État 1:
le compteur est en train de présenter à la RAM une adresse correspondant à une instruction.
Le processeur récupère sur le bus Q[7:0] la contenu de la RAM à cette adresse, c’est à dire l’instruction à effectuer.
il faut stocker cette instruction pour plus tard (quand on effectuera l’opération demandée).
On ajoute donc à l’automate un registre sur 8 bits disposant d’un enable (8 bascules DFFE en parallèle).
L’entrée de ce registre est reliée au bus Q[7:0] (sortie de la RAM)
Le signal d’enable de ce registre est mis à l’état haut seulement pendant l’état 1 –> stockage de l’instruction dans le registre
État 2:
le compteur est en train de présenter à la RAM une adresse correspondant aux premier opérande.
le processeur récupère sur le bus Q[7:0] la contenu de la RAM à cette adresse, c’est à dire l’opérande 1…
il faut stocker cet opérande, donc re-belotte, on ajoute un registre 8 bits avec enable, relié à la sortie de la RAM (Q[7:0]).
l’enable est mis à l’état haut seulement pendant l’état 2.
État 3:
le compteur est en train de présenter à la RAM une adresse correspondant aux deuxième opérande.
le processeur récupère sur le bus Q[7:0] la contenu de la RAM à cette adresse, c’est à dire l’opérande 2…
comme d’habitude on stocke cet opérande dans un registre 8 bits, dont l’enable est piloté à l’état haut seulement pendant ce cycle-ci.
Remarque : on peut se dire que ce n’est pas la peine de stocker cet opérande, car on dispose dès à présent de toutes les données pour effectuer le calcul : l’instruction dans un registre, l’opérande dans un autre registre, et le deuxième opérande sur le bus Q[7:0]. Mais il faudrait alors stocker le résultat dans un registre 8 bits, car on ne fait son stockage en RAM qu’au prochain cycle…Alors qu’ici, le calcul et le stockage seront faits en bloc au prochain cycle (donc pas besoin de stocker le résultat dans un registre). Au total, dans les deux approches, le nombre de registres est le même, et ce ne sont que des considérations de chemin critique qui permettront de déterminer la meilleure des deux méthodes…
État 4:
le compteur est en train de présenter à la RAM une adresse correspondant au résultat à stocker.
l’automate dispose dans ses trois registres de toutes les données pour effectuer le calcul. Il suffit d’ajouter une fonction combinatoire pure, pour produire le résultat.
La sortie de cette fonction combinatoire sera reliée au bus d’entrée de la RAM.
L’équation de cette fonction sera du genre : RES[7:0] = (si INSTRUCTION="00000100" : OP_1[7:0] + OP_2[7:0], sinon OP_1[7:0] - OP_2[7:0])
Une telle fonction combinatoire a été réalisée au TP numéro 2…(ALU)
Parallèlement, l’automate doit piloter le signal WRITE de la RAM à l’état haut, pour dire à la RAM de stocker à l’adresse courante la sortie de la fonction de calcul.
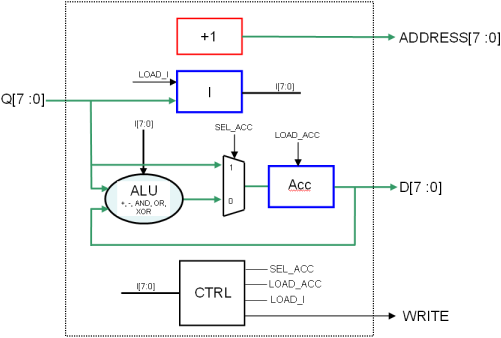
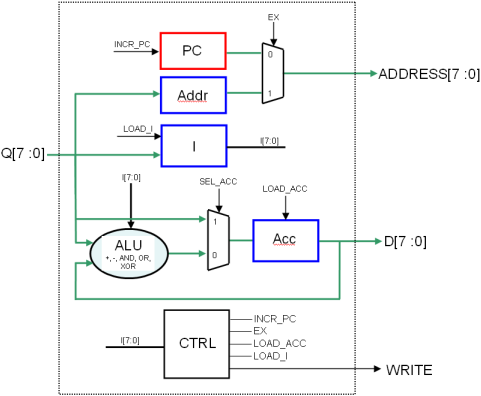
On obtient donc l’architecture suivante pour notre processeur :
En rouge : le compteur d’adresse courante
En bleu : les trois registres 8 bits, les signaux load sont les enable
En noir rond : la fonction combinatoire de calcul proprement dite (ALU)
En noir carré : la machine à état qui séquence tout ça…
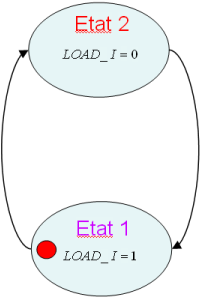
L'automate (CTRL) est présenté en figure 1.4 et son graphe d’états en figure 1.5.
Figure 1.4: Architecture de la première version du nanoprocesseur
L'automate a quatre états, parcourus de façon linéaire, sans condition sur les transitions.
Il dispose de 4 sorties, chacune d’entre elles à l’état haut dans un seul état de l'automate. Un codage "one-hot", consistant à matérialiser chaque état par un registre est donc très approprié.
L’implémentation en registre a déjà été vue (registres les uns à la suite des autres), et ne sera pas détaillée ici. Les sorties des registres donnent directement les sorties de l'automate…
Figure 1.5: Graphe d'états de l'automate linéaire
Réponse 2
Plusieurs possibilités, leur nombre est limité seulement par votre imagination. Voici quelques exemples :
Garder le résultat de chaque opération en mémoire, et définir une nouvelle addition qui opère sur un opérande en RAM et celle qu’on a gardé.
L’inconvénient est qu’on rajoute une instruction pour chaque type d’opération, que cette nouvelle opération, ne nécessitant qu’un seul opérande en RAM pourra être effectuée en 3 cycles au lieu de 4, et que ça risque de compliquer la machine à état si on veut l’optimiser (certaines opération en 3 cycles, d’autres en 4)…
Définir des opérations de manipulation de la RAM, et grâce à elles recopier le résultat en RAM à l’endroit d’une des deux opérandes de la prochaine instruction. C’est bien compliqué…
Définir une nouvelle addition qui opère sur un opérande à l’endroit habituel en RAM, et sur un autre opérande situé à l’adresse (instruction - 1)…
Utiliser la première solution, mais pour simplifier les choses (et par cohérence) supprimer les opérations sur deux opérandes en RAM. Toutes les opérations (à deux opérandes) se feront entre un opérande en RAM, et un gardé dans un registre interne au processeur. Et pour rendre cela possible, on définit deux nouvelles instructions : chargement de ce registre à partir d’une donnée en RAM, et stockage du contenu de ce registre en RAM. C’est l’objet de la suite !
Réponses 3 et 4
Chaque opération ne nécessite plus qu’un seul opérande :
pour le load, c’est normal !
pour le store, aucun opérande. Par contre, en RAM, à la suite de l’instruction store, il doit y avoir un emplacement libre pour stocker le contenu de l’accumulateur
pour les opération à deux opérandes, l’un est en RAM, l’autre est interne à l’automate (c’est l’accumulateur)
Le contenu de la RAM se présentera donc maintenant ainsi :
adresse
type du mot stocké
exemple
effet
0
instruction
load
1
donnée
3
l’accumulateur contient maintenant 3
2
instruction
+
3
donnée
4
l’accumulateur contient maintenant 7
4
instruction
-
5
donnée
1
l’accumulateur contient maintenant 6
6
instruction
store
7
donnée
X
après l’exécution du programme cet emplacement en RAM contiendra “6”
On remarque donc qu’une adresse sur deux contient une instruction, une sur deux contient une donnée (soit opérande, soit stockage du contenu de l’accumulateur)…
Pour effectuer les calculs, le processeur n’a plus besoin de connaître que deux informations : l’instruction et l’opérande. On garde donc le registre d’instruction (8 bits) qui stocke l’instruction à effectuer pendant qu’on va chercher l’opérande en RAM.
Par contre, auparavant on parcourait 4 emplacements en RAM pour chaque instructions, d’où une machine à états à 4 cycles. Maintenant on ne parcourt plus que 2 emplacements en RAM, donc une machine à état à 2 cycles devrait convenir…
A chaque instruction, le processeur effectuera ceci :
Pour une opération "normale" :
aller chercher l’instruction en RAM, la stocker dans le registre d’instruction
aller lire l’opérande en RAM, effectuer le calcul et stocker le résultat dans l’accumulateur (opération)
Pour un "load" :
aller chercher l’instruction en RAM, la stocker dans le registre d’instruction
aller lire l’opérande en RAM, et le stocker dans l’accumulateur (opération)
Pour un "store" :
aller chercher l’instruction en RAM, la stocker dans le registre d’instruction
écrire le contenu de l’accumulateur en RAM à l’adresse courante
Chaque instruction est donc traitée de façon très similaire :
un cycle de récupération de l’instruction (dans lequel l’enable du registre d’instruction est mis à l’état haut).
Lors du second cycle, l’accumulateur peut subir trois traitements différents :
pour une opération (+, −, AND, XOR, OR), l’accumulateur se voit modifié et chargé avec le résultat de l’opération
pour un load, l’accumulateur est modifié aussi, et chargé avec la donnée sortant de la RAM
pour un store par contre, l’accumulateur n’est pas modifié…
En entrée de l’accumulateur on mettra donc un multiplexeur qui présentera soit le résultat de l’opération en cours (si on exécute une opération standard), soit le contenu de la RAM (si on exécute un load). De plus, dans ces deux cas, le signal enable de l’accumulateur sera mis à l’état haut (pour autoriser sa modification) dans l’état 2 (quand on accède à la partie donnée de la RAM) Dans le cas d’un store, on laisse l’enable de l’accumulateur à l’état bas pour ne pas le modifier.
En d’autre termes, le signal de validation du chargement de l’accumulateur a pour équation en pseudo-langage :
LOAD_ACC = (Instruction <> STORE) ET (Etat = état 2)
Le pilotage du multiplexeur en entrée de l’accumulateur aura pour équation quelque chose du genre :
ACC =
si (Instruction == LOAD) alors Q[7:0],
si (Instruction == opération) alors ALU(ACC, Q[7:0]),
si (Instruction == STORE) alors peu importe…)
Ce qui se simplifie en :
ACC =
si (Instruction == LOAD) alors Q[7:0],
sinon ALU(ACC, Q[7:0]))
La sortie de l’accumulateur est branchée simultanément
sur le bus d’entrée de la RAM (pour le cas d'une instruction "store")
sur l’ALU (qui implémente, selon l’instruction à effectuer, l’addition, la soustraction, le XOR, etc…)
Enfin la génération du signal d’écriture en RAM est simple : il est mis à l’état haut quand l’instruction est un STORE, et qu’on est dans l’état 2. Le contenu de l’accumulateur est présenté sur l’entrée de la RAM (cf. ci dessus), l’adresse courante est sur le bus d’adresse de la RAM, la RAM est donc mise à jour avec la bonne valeur…
un automate générant les signaux LOAD_I, LOAD_ACC, WRITE et le contrôle du multiplexeur
Remarque : Les signaux générés par l'automate ne dépendent pas seulement de l’état courant de l'automate, mais aussi de la nature de l’instruction à exécuter. On nomme ce genre d'automate "machine de Mealy")
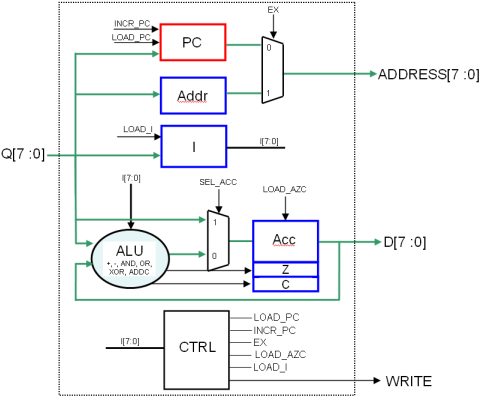
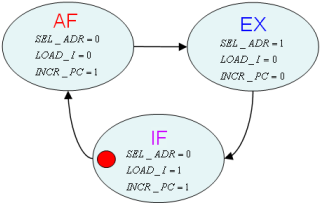
L’architecture globale est celle représentée sur la figure 1.6, et son graphe d’états en figure 1.7
Figure 1.6: Architecture de la deuxième version du NanoProcesseur
Figure 1.7: Graphe d'états de la deuxième version du NanoProcesseur
Maintenant, on n’accède plus à la RAM de façon linéaire. Dans l’exemple de programme donné, les adresses présentées à la RAM seront celles-ci :
0
1
100
2
3
101
4
5
102
…
Les adresses de code sont globalement linéaires (0, 1, 2, 3, …), celles des données ne le sont pas (elles sont arbitraires). Il faut donc présenter sur le bus d’adresse RAM
soit le compteur d’adresse pendant les deux premiers cycles (et on l’incrémente à chaque fois)
soit le contenu du registre d’adresse (adresse de l’opérande à aller chercher) pendant le troisième cycle (et ici le compteur d’adresse ne doit pas être incrémenté)
donc : multiplexeur…
De plus, le compteur d’adresse doit être piloté par un signal INCR_PC : il n’est incrémenté que si INCR_PC est à l’état haut.
Le registre d’adresse est chargé au cycle numéro 2. Son contenu n’est utile qu’au cycle numéro 3. Il n’est donc pas nécessaire de le piloter avec un enable…Il peut rester tout le temps actif : son contenu sera indéterminé pendant les cycles 1 et 2, mais ce n’est pas grave, il n’est pas utilisé pendant ces cycles là…
L’architecture globale est donc celle représentée sur la figure 1.8, et son graphe d’états en figure 1.9.
Figure 1.8: Architecture de la troisième version
Figure 1.9 : Graphe d'états de la troisième version
C’est, ici encore, une machine de Mealy, et ses équations sont :
La génération de C et Z est combinatoire et peut être effectuée par l’ALU.
Il suffit juste de rajouter deux registres 1 bits pour stocker ces deux signaux, pilotés par le même enable que l’accumulateur (LOAD_ACC, qu’on appellera maintenant LOAD_AZC). On considérera donc que Z et C font partie de l’accumulateur (qui devient donc un registre sur 10 bits : 8 de donnée, 1 pour Z, un pour C).
Remarque : le fonctionnement de Z et C ici n’est pas tout à fait standard !..
Il suffit de faire entrer C sur la retenue entrante de l’addition ou de la soustraction…
Réponse 7
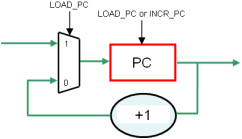
Pour implémenter les sauts, il suffit de se donner la possibilité de remplacer le contenu de PC par la valeur lue en RAM.
PC devient donc un peu plus complexe. C’est globalement un compteur, mais :
il est incrémenté si son signal de commandeINCR_PC = 1
il est chargé avec une nouvelle valeur si un signal de chargement LOAD_PC = 1
Enfin, si LOAD_PC et INCR_PC valent 1, LOAD_PC a la priorité...
Ceci peut être implémenté comme indiqué en la figure 1.10.
Figure 1.10: Implémentation du PC
Pour simplifier les schémas, nous nommerons PC l'ensemble du bloc de la figure 1.10.
Il faut maintenant générer le signal LOAD_PC. Ce signal sera aussi généré par la machine à états CTRL. Le PC doit être remplacé lorsqu’on exécute un saut, et que le condition du saut est vérifiée. La nouvelle valeur est présente sur le bus de sortie de la RAM pendant le cycle 2.
On aura donc une équation du style :
LOAD_PC = si (
(I[7:0] == JMP)
ou (I[7:0] == JNC et C == 0)
ou (I[7:0] == JNZ et Z == 0))
et (état = etat 2), alors 1,
sinon 0.
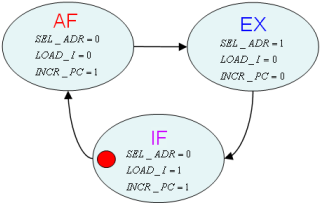
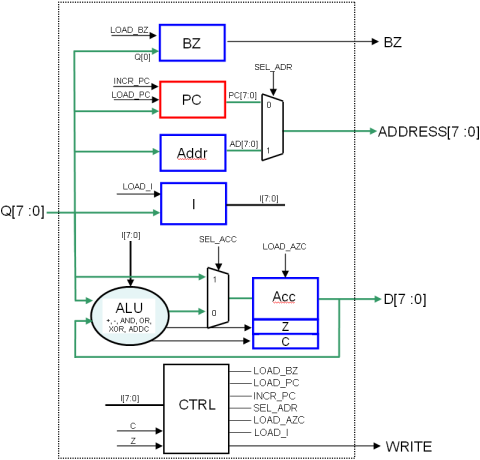
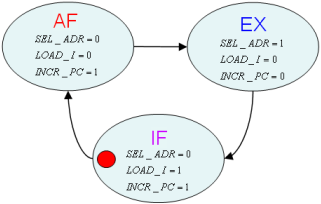
L’architecture globale est donc celle représentée sur la figure 1.11, avec un automate CTRL à peine modifié (même graphe d’état) représenté figure 1.12.
Figure 1.11: Architecture de la quatrième version du nanoprocesseur
Figure 1.2: Graphe d'états de la quatrième version du nanoprocesseur
SEL_ACC = (I[7:0] == LOAD)
LOAD_ACC = (I[7:0] <> (STORE ou saut)) ET (Etat = Ex)
WRITE = (I[7:0] == STORE) ET (Etat = Ex)
LOAD_PC = si (I[7:0] == JMP ou I[7:0] == JNC et C == 0 ou I[7:0] == JNZ et Z == 0) et (état = Ad), alors 1, sinon 0
Réponse 8
L’instruction NOP ne fait rien. Elle n’a pas besoin d’opérande, et pourrait donc être stockée sur un seul octet (au lieu de deux pour les autres).
Mais cela compliquerait la gestion de l'automate pour générer les signaux LOAD_PC et INCR_PC. De plus, cela pourrait poser d’autres problèmes (cf. les optimisations).
On peut donc accepter de perdre un octet de mémoire, et ne rien changer à l’organisation de la mémoire. L’instruction NOP sera accompagnée d’un opérande qui ne servira a rien... Une instruction sera toujours exécutée en trois cycles. La seule modification de la machine à état sera l’équation suivante :
LOAD_ACC = (I[7:0] <> (STORE ou saut ou NOP)) ET (Etat = Ex)
Ces opérations sont combinatoires et seront donc implémentées dans l’ALU.
Remarque : comme le NOP, elles ne nécessitent pas d’opérande. De même, pour garder une cohérence (nous optimiserons ça plus tard), on garde un codage des instructions sur deux octets. Pour ROR et ROL, le deuxième octet n’a pas de signification...